-
18 jul 2024Industrial companies are spearheading the fight against climate change
-
-
09 jul 2024Energía eléctrica y renovablesModular construction: Pros and cons
-

Xing Li, P.Eng.
Practice Leader - Civil, Structural and Geotechnical
-
-
28 jun 2024Energía eléctrica y renovablesHow can energy efficiency support decarbonization efforts?
-

Pierre-Luc Bouchard
Principal Engineer | Energy and Air Quality
-
-
25 jun 2024Valuing Indigenous knowledge to develop natural resources sustainably
-
oct 22, 2020
Machine learning: A powerful asset for better use of your data
-
What is machine learning?
Machine learning is a subdomain of artificial intelligence (AI) that is based on mathematical and statistical approaches and enables computers to learn from data. Unlike traditional programming, where humans need to write a program and provide the computer with inputs to get output results, a machine learning algorithm takes inputs and expected results and generates a program (a mathematical function) for output.
-
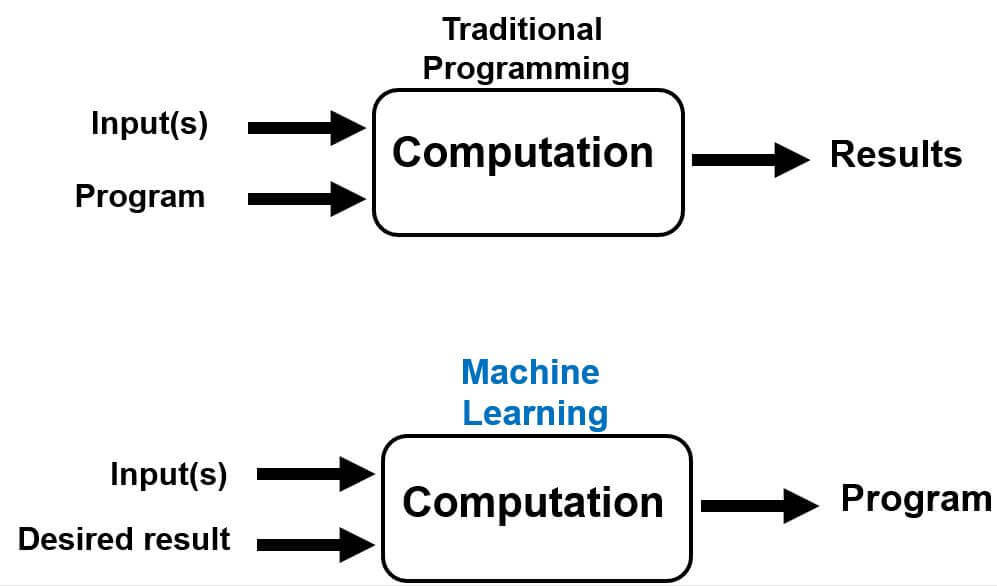
-
As a result, the machine learning algorithm can learn from historical data, called training data, to generate a model that would allow for predictions using new unknown data, called test data.
-

-
Types of machine learning
There are different types of machine learning, depending on the available data and learning methods. In this blog article, we will focus on two types: supervised and unsupervised.
Supervised learning
This type of learning enables the algorithm to learn from submitted annotated or labelled data. In other words, observations and their labels are found in the training data.
Example of algorithms: data classification
In an application to recognize individuals’ images, the algorithm is trained using multiple images. Since each image is labelled with the name of the corresponding person, the algorithm can learn the characteristics of each individual based on several images of the same person. With new images of individuals, the classification algorithm can predict the name of the person associated with each image and build the ability to generalize about new images it has never seen before.
-

-
Unsupervised learning
Unlike supervised learning, where the algorithm has the advantage of being trained on observations and their labels, the unsupervised learning algorithm only has observations, without their labels. As a result, it needs to discover the observation’s characteristic structure on its own, without any human assistance, and determine the data labels.
Example of algorithms: data partitioning
Data partitioning, also called clustering, subdivides a set of data into different groups to maximize the similarity between individuals from the same group and minimize the similarity between individuals who belong to different groups. For example, a clustering algorithm can be trained to identify different objects in an image and assign the same label to similar objects. When unsupervised, the learning algorithm should define the labels in the data.
-

-
Beware of overfitting and underfitting!
When the algorithms are trained, some issues may appear and affect the algorithm’s prediction ability on new data.
Overfitting occurs when the algorithm learns by heart from the training data, so that prediction errors are very low on the training data, but high for new observations (or test data). Cross-validation for optimal selection of model parameter values, bagging and regularization are all known solutions to mitigate overfitting.
Underfitting occurs when the algorithm does not learn enough about the training data, resulting in high prediction errors on both the training and test data. This can be caused by poor model selection (e.g., an overly simple linear model). Solutions for underfitting include adding more features to the initial model, increasing its complexity and increasing training time and data size.
Preparing your data well
In a data science project, 80% of the time will be dedicated to collecting and preparing data. In fact, a successful data science project begins with good data preparation, which should not be underestimated.
Several data categories can be collected to carry out your projects, such as text data, images and videos. They can be internal (e.g., data from vibration measuring sensors, electrical currents, motor temperature) or external (e.g., weather data and other public data relevant to the problem). This raw data from various sources is generally unstructured.
After the data is collected, the next step is to structure and centralize it into a single structure available across the organization. Structuring your data involves cleaning it (e.g., removing irrelevant data and duplicates), formatting it (e.g., type conversion, imputation, syntax errors, standardization, value scaling) and assessing its quality (completeness, consistency and uniformity).
Select your model
After properly preparing your data, the next step in your data science project is naturally to select your machine learning model. Depending on the form of training you need to use (supervised, unsupervised) and the type of algorithms you want to set up (classification, regression, clustering), there are several options (e.g., decision trees, neural networks, support vector machines, K-Means, DBScan). But which model should you choose?
It is generally difficult to guess which model is the most appropriate, because it depends on data size and quality as well as the type of problems you want to solve. Each model has its pros and cons. It is recommended to test several machine learning models and compare the results of various models on the same data. The performance of a model can vary (increase or decrease) depending on its parameter values; choosing the right model parameter values allows you to get better performance, and vice versa. Finally, be aware that the performance of your selected model is not guaranteed forever, especially if your data tends to change over time. So, it is important to re-train your model on a regular basis to keep it updated and to compare it with other models to ensure it still best meets your needs.
How to start your AI project?
The best way to start a project in a little-known field is to be supported by a partner who has the relevant expertise. Our experts in AI, advanced data analysis and industrial IT are here to guide you in your data science project and to advise you in making the right choices, whether for preparing your data or selecting your learning algorithm.
Try our new AI jump start program to quickly launch your first AI project and make it a success. This three- to four-week program will help you find out where your organization stands in terms of AI and then clearly identify the steps you need to prioritize to maximize your investments as quickly as possible. A team of BBA experts will help you define your AI project and guide you in developing a short- and long-term AI vision for your organization.
BBA also offers training in machine learning that provides the opportunity for you to discover this current field and learn about the latest market trends.
Contact us to find out more and start your AI adventure!
This content is for general information purposes only. All rights reserved ©BBA



